As a geek with a passion for both SQLite and replication algorithms, I've enjoyed following the development of the new sqlite3_rsync utility in the SQLite project.
The utility employs a bandwidth-efficient algorithm to synchronize new and modified pages from an origin SQLite database to a replica. You can learn more about the new utility here and try it out by following the instructions here.
Curious about its workings, I reviewed the code, which can be found in SQLite's Source Repository here or from the GitHub mirror here (retrieved on 2024-11-02).
Here are some of the highlights:
Replication Protocol
The utility initiates two processes: an origin process and a replica process. These are launched in the main() function on lines 1771-1792:
int main(int argc, char const * const *argv){
...
if( isOrigin ){
...
originSide(&ctx);
return 0;
}
if( isReplica ){
...
replicaSide(&ctx);
return 0;
}
}
The two sides communicate using a custom wire protocol. They follow this sequence of commands for the happy path:
ORIGIN_BEGIN- The origin starts the replication process by sending this command with some configuration values so the replica can validate compatibility.REPLICA_HASH- The replica computes the hash of all the pages in its database and sends them back to the origin in sequential order. For each hash, the origin checks if it has the same page. If not, it adds the page number to a list of pages to be transferred.REPLICA_READY- Once all the hashes have been sent, the replica sends this command to let the origin know it is ready to receive the pages that need to be updated.ORIGIN_PAGE- For each page that needs to be updated, the origin sends this command along with the page number and page data to the replica.ORIGIN_TXN- The origin sends this command once all the pages needing updating have been sent to signal the replica to commit the update transaction.ORIGIN_END- The origin sends this command to tell the replica to quit.
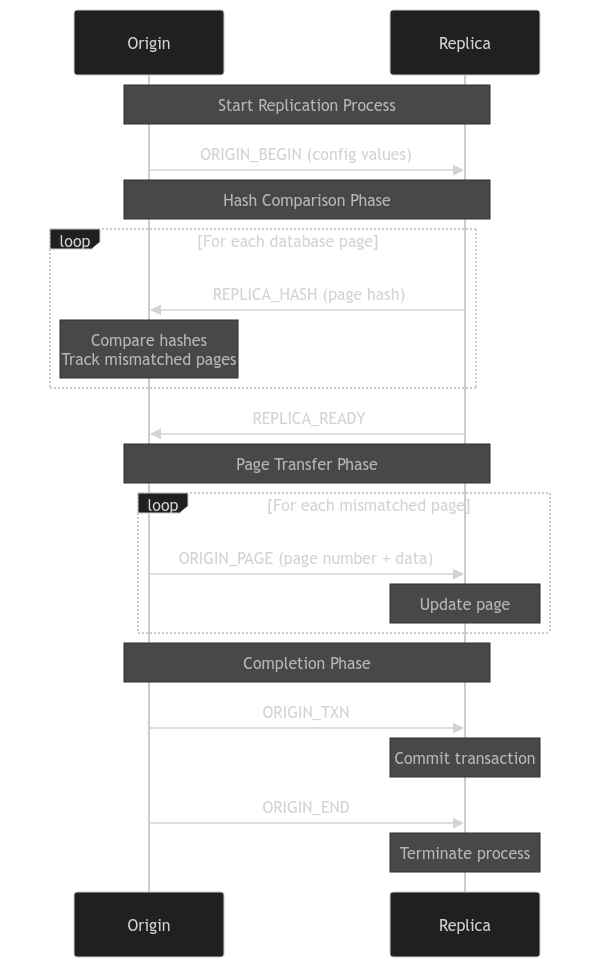
In addition to the happy path, there are commands for error handling:
ORIGIN_ERROR- The origin sends this to signal a fatal error occurred, terminating replication.REPLICA_ERROR- The replica sends this to signal a fatal error occurred, terminating replication.ORIGIN_MSG- The origin sends informational/warning messages to the replica.REPLICA_MSG- The replica sends informational/warning messages to the origin.
There are also a few commands to handle special cases:
REPLICA_BEGIN- The replica only sends this to request a different wire protocol version.REPLICA_END- The replica sends this only when using the--commcheckoption to verify connectivity.
Using SQL for Computations
The utility cleverly uses SQL to compute hashes and perform comparisons (line numbers refer to where the prepared statements are created, the snippets shown are derived from the original code for clarity):
- Hashes are initially computed on the replica (lines 1480-1482):
SELECT hash(data) FROM sqlite_dbpage('replica')
WHERE pgno<=min(%d,%d)
ORDER BY pgno
- The origin compares hashes from the replica (lines 1283-1290):
-- Create a temporary table to store page numbers with mismatched hashes
CREATE TEMP TABLE badHash(pgno INTEGER PRIMARY KEY);
-- Compare the (pgno, hash) tuple from the replica with the origin's contents
SELECT pgno FROM sqlite_dbpage('main')
WHERE pgno=?1 AND hash(data)!=?2;
-- If there is a mismatch, add the page number to the temporary table
INSERT INTO badHash VALUES(?);
- The origin adds all pages with page numbers greater than the maximum page number from the replica to the badHash table (lines 1321-1324):
WITH RECURSIVE c(n) AS
(VALUES(%d) UNION ALL SELECT n+1 FROM c WHERE n<%d)
INSERT INTO badHash SELECT n FROM c;
- The origin retrieves all pages identified in the badHash table for transfer to the replica (lines 1328-1329):
SELECT pgno, data
FROM badHash JOIN sqlite_dbpage('main') USING(pgno);
- The replica inserts or updates pages received from the origin (lines 1528-1529):
INSERT INTO sqlite_dbpage(pgno,data,schema)VALUES(?1,?2,'replica');
Custom Hash Function Implementation
One of the more interesting technical details of the sqlite3_rsync utility is its use of a custom hash function.
For this use case, a full cryptographic hash function is unnecessary and would be computationally expensive. Instead of relying on a standard hashing library function, sqlite3_rsync uses a variant of the SHA-3 algorithm with fewer rounds, 6 instead of the standard 24.
Fewer rounds mean the hash function is faster, but it is also less secure. However, for the use case of comparing database pages, security is not a concern.
The full hash function can be found on lines 516-805. Here's a short, fun excerpt from the mixing function:
/* v---- Number of rounds. SHA3 has 24 here. */
for(i=0; i<6; i++){
c0 = a00^a10^a20^a30^a40;
c1 = a01^a11^a21^a31^a41;
c2 = a02^a12^a22^a32^a42;
c3 = a03^a13^a23^a33^a43;
c4 = a04^a14^a24^a34^a44;
d0 = c4^ROL64(c1, 1);
d1 = c0^ROL64(c2, 1);
d2 = c1^ROL64(c3, 1);
d3 = c2^ROL64(c4, 1);
d4 = c3^ROL64(c0, 1);
The hash function is registered as a new SQL function hash() in the origin and replica database for convenient use in SQL statements.
--
Conclusion
Because the authors implemented the sqlite3_rsync utility in a self-contained, ~2000 line C program that almost exclusively uses procedural code, it is easy to follow how it works. Both the high-level design and the low-level implementation are straightforward and easy to understand.
I'm excited to see this new utility added to SQLite. It adds a more efficient option to the toolset for replicating SQLite databases.